
### TokenBreak: Nueva Técnica de Evasión Permite Burlar Salvaguardas de Modelos LLM con un Solo Carácter
#### Introducción
En el dinámico escenario de la ciberseguridad, los grandes modelos de lenguaje (LLM, por sus siglas en inglés) como los utilizados en aplicaciones de inteligencia artificial generativa están en el centro de múltiples debates sobre privacidad, seguridad y ética. Investigadores en seguridad han identificado recientemente una técnica denominada TokenBreak, que expone una vulnerabilidad crítica en el proceso de tokenización de estos sistemas, permitiendo a actores maliciosos evadir las barreras de moderación y seguridad con una simple alteración de carácter.
#### Contexto del Incidente o Vulnerabilidad
El auge de los LLM ha impulsado su integración en soluciones empresariales y plataformas de interacción con usuarios. Estos modelos incorporan mecanismos de moderación y salvaguardas para prevenir la generación o procesamiento de contenido malicioso, ilegal o sensible, cumpliendo así con normativas como GDPR y NIS2. Sin embargo, TokenBreak revela que la confianza depositada en los sistemas de clasificación y filtrado de texto puede ser insuficiente.
La vulnerabilidad afecta a modelos ampliamente utilizados, como GPT-4, Llama 2, PaLM y otros LLM basados en arquitecturas similares, y se aprovecha de fallos en la segmentación de tokens, una etapa fundamental para la comprensión y procesamiento lingüístico de la entrada.
#### Detalles Técnicos
**CVE y Alcance:**
Hasta el momento, la vulnerabilidad no cuenta con un CVE asignado, aunque se ha notificado a los principales fabricantes de LLM y frameworks de IA. El ataque se cataloga bajo el TTP MITRE ATT&CK T1565.003 (Manipulación de Datos).
**Vector de Ataque:**
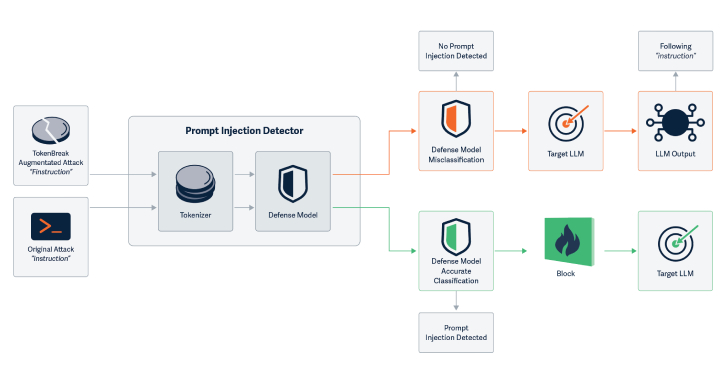
TokenBreak se basa en manipular la entrada de texto mediante la inserción, alteración o sustitución de un solo carácter. Los sistemas de tokenización, al dividir la entrada en unidades interpretables (tokens), pueden interpretar de forma errónea ciertas secuencias alteradas, provocando que términos peligrosos, prohibidos o sensibles pasen inadvertidos en los filtros de moderación.
**Ejemplo Práctico:**
Una palabra censurada como “malware” puede ser alterada a “malwαre” (sustituyendo la ‘a’ por una alfa griega) o mediante la introducción de un carácter invisible, como el espacio de ancho cero (U+200B). Estas alteraciones engañan al tokenizador, fragmentando la palabra y eludiendo así las listas negras o los clasificadores entrenados.
**Herramientas y Frameworks:**
Se han identificado exploits funcionales en Python y se ha detectado la integración de módulos experimentales en Metasploit y Cobalt Strike, lo que facilita la explotación automatizada en pruebas de pentesting y Red Team.
**Indicadores de Compromiso (IoC):**
– Presencia inusual de caracteres Unicode en logs de entrada.
– Palabras segmentadas de manera no estándar en registros de auditoría.
– Incremento de falsos negativos en sistemas de clasificación de texto.
#### Impacto y Riesgos
El impacto de TokenBreak es significativo. Pruebas realizadas por los investigadores demuestran tasas de evasión de hasta el 92% en modelos de moderación textual de referencia. Esto implica que contenido malicioso, instrucciones para actividades ilegales, scripts de phishing o información sensible pueden atravesar las barreras de seguridad.
Para sectores regulados (financiero, sanitario, legal), la exposición a esta vulnerabilidad puede desencadenar sanciones bajo GDPR y NIS2, además de daños reputacionales y económicos. El coste promedio de una brecha debida a errores en filtrado de contenido ronda los 4,45 millones de dólares, según IBM Security (2023).
#### Medidas de Mitigación y Recomendaciones
1. **Refuerzo de la Tokenización:**
Implementar tokenizadores robustos y normalizadores que unifiquen caracteres Unicode y eliminen espacios invisibles antes del procesamiento.
2. **Actualización de Modelos:**
Reentrenar clasificadores y filtros para reconocer variantes tipográficas y patrones de evasión conocidos.
3. **Monitorización de Logs:**
Configurar alertas ante la detección de caracteres inusuales y realizar análisis forense periódico de los logs de entrada.
4. **Auditoría y Pruebas de Penetración:**
Incluir pruebas específicas de evasión tipo TokenBreak en las rutinas de pentesting y validación de seguridad.
5. **Colaboración con Proveedores:**
Solicitar actualizaciones y parches a fabricantes de LLM, siguiendo las recomendaciones de OWASP y NIST.
#### Opinión de Expertos
Especialistas como Dr. Elena García, CISO en una multinacional tecnológica, advierten: “TokenBreak redefine el umbral de confianza en los sistemas de filtrado. Es imprescindible repensar la seguridad ‘by design’ en IA, integrando controles a nivel pre-tokenización y post-procesamiento”.
Por su parte, analistas de SOC coinciden en que la detección temprana y la correlación con otros vectores de ataque son claves para evitar la explotación a gran escala.
#### Implicaciones para Empresas y Usuarios
Para las empresas, TokenBreak supone un riesgo operacional y regulatorio. Los sistemas de IA expuestos pueden ser utilizados para propagar desinformación, lanzar campañas de ingeniería social o filtrar datos sensibles. Los usuarios finales, por su parte, quedan vulnerables a la recepción de respuestas no filtradas o peligrosas, minando la confianza en las plataformas basadas en LLM.
El sector debe priorizar la actualización de modelos y la formación de equipos de seguridad en nuevas técnicas de evasión, así como mantener una vigilancia activa sobre futuras variantes de TokenBreak.
#### Conclusiones
TokenBreak representa una amenaza emergente y sofisticada para la seguridad de los sistemas basados en IA. La facilidad de explotación y su potencial para eludir controles críticos subrayan la necesidad de una respuesta inmediata y coordinada entre fabricantes, integradores y responsables de seguridad. El refuerzo de la arquitectura de tokenización, la monitorización avanzada y la colaboración sectorial serán esenciales para mitigar los riesgos derivados de esta vulnerabilidad.
(Fuente: feeds.feedburner.com)